







Introduction
The Deep learning is increasingly being applied in the aquaculture industry to provide technical support for precision farming,1 fish detection,2 disease identification,3 population statistics,4 etc. Feng et al5 used Multi-scale Retinex (MSRCR) algorithm for color restoration of images with multimetric-driven contrast-constrained adaptive histogram equalization (mdc) to improve the image clarity and combined the proposed Multi-Step Image Pre-enhancement (MIPS) module with the lightweight EfficientNet network, which significantly improved the intensity of the feeding behavior of fishes in the classification accuracy. Jiang et al6 utilized migration learning and inter-layer fusion mechanisms for recognizing 10 fish species with complex backgrounds. The experimental results show that the model can improve the ability of fish classification and recognition in complex underwater scenarios, which can support the study of fishery resource distribution. Yu et al7 established the Fish-Keypoints dataset and used deep learning techniques to detect the key points of the fish and combined the binocular camera system with a 3D coordinate system to measure the length of the fish, which was tested in both water and land environments, and the results showed that the relative error was small and could accurately detect the key points of the fish. Yu et al8 proposed an improved U-net segmentation and measurement algorithm, which uses the expansion convolution to replace the convolution in the original U-net to expand part of the convolutional sensory field and realize more accurate segmentation of large targets in the scene. It is combined with the line fitting method based on the least squares method to accurately measure the body length and body width of tilted fish, which provides technical support for the batch detection of good fish species. Zheng et al.9 realized a real-time recognition method for single fish by integrating video object segmentation with the YOLOv7 detection algorithm in complex underwater environments, which effectively improves the accuracy and efficiency of fish individual recognition. Li et al10 based on YOLOv5, referenced Res2Net residual structure and coordinate attention mechanism instead of the original Bottleneck to realize an accurate and fast fish detection method in fisheries. Zhang et al11 based on YOLOv8n proposed the integration of GELU activation function, MPDIoU, and the fusion of C2f-FAM and C2f-MSCA modules in the backbone network to enhance YOLOv8 with high performance in environments with high turbidity and high number of fishes.
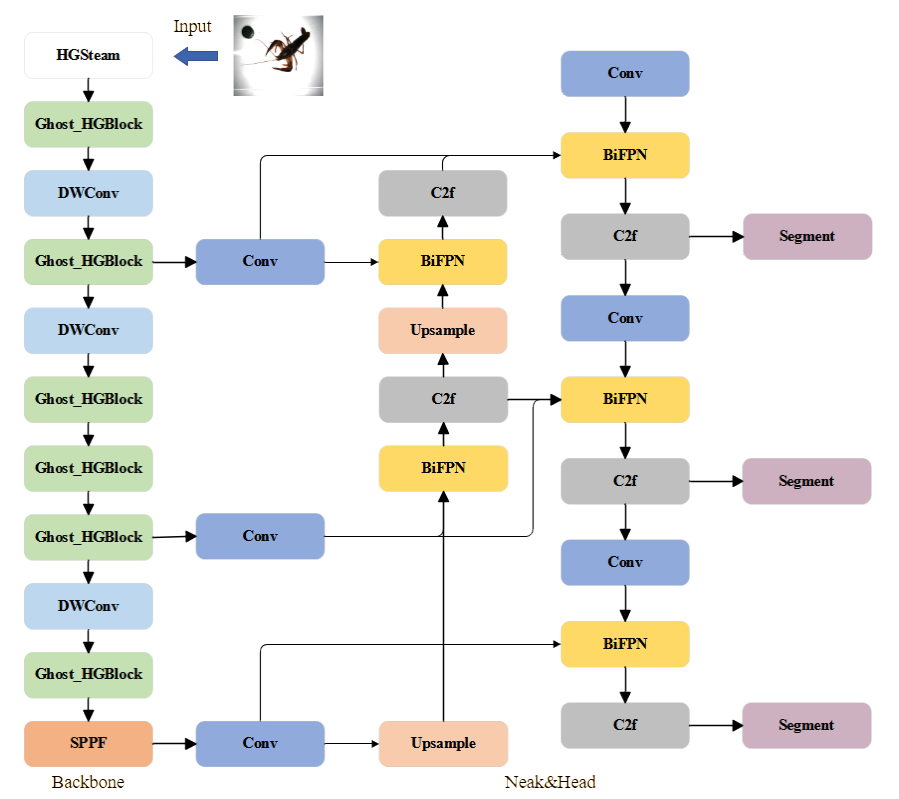
In comparison to the existing research on intelligent technology for fish, the large-scale culture of crayfish is less researched for its intelligence due to its late development. To achieve intelligent grading of crayfish, this paper proposes a method for detecting the main trunk of crayfish bodies based on an improved instance segmentation model, GHBSeg-YOLOv8. Our model features high accuracy, low parameter volume, and small size. It is friendly to low-performance hardware devices, which is conducive to further deployment to mobile devices. The lightweight improvement of the model is accomplished by using GhostHGNetV2, a lightweight backbone network based on deeply separable convolution with the advantages of efficient feature extraction capability and high accuracy. In addition, the study further reduces the model’s weight by optimizing the neck structure of YOLOv8-seg with BiFPN modules. The parameters, weights and GFLOPs of the GHBSeg-YOLOv8 model were significantly reduced by the improved model mAP compared to the base model YOLOv8n-seg.
This study’s contribution can be summarized as follows: This paper proposes a method for segmenting the crayfish body trunk based on an improved single-stage instance segmentation model GHBSeg-YOLOv8. Our method can frame the shrimp body trunk at the pixel level. The method proposed in this paper is highly accurate, small in size, and friendly to low-performance devices. A method combining the backbone network GhostHGNetV2 and BiFPN modules is proposed, greatly reducing the model volume and having high detection accuracy.
Materials and Methods
Improved model construction for YOLOv8n-seg
On the basis of the YOLOv8n model, Ghost convolution is introduced to improve the model performance, and it is combined with HGNetV2 to replace the original backbone network to simplify the model structure while maintaining high accuracy. At the same time, Bidirectional Feature Pyramid Network (BiFPN) is added, which enables the model to carry out multi - scale feature fusion more quickly and, consequently, further reduces the number of model parameters. Finally, a new segmentation network is constructed. The model GHBSeg - YOLOv8 is shown in Fig. 1, and the specific optimization of each module and structure is described in the following subsections.

GhostNet Module
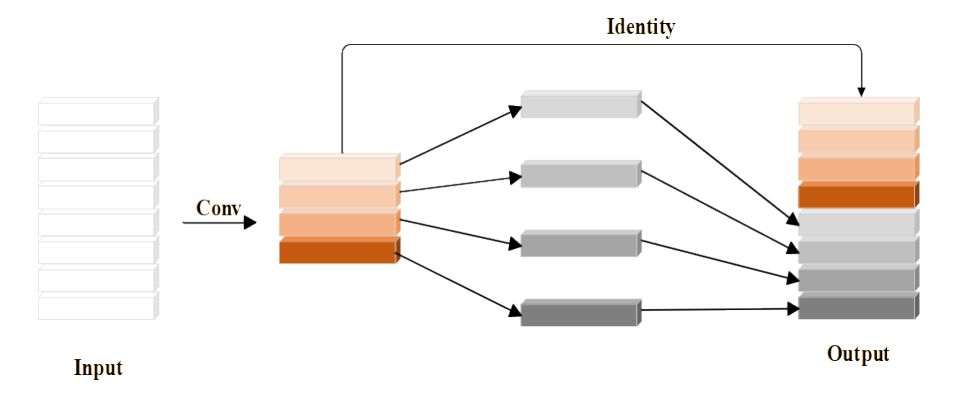
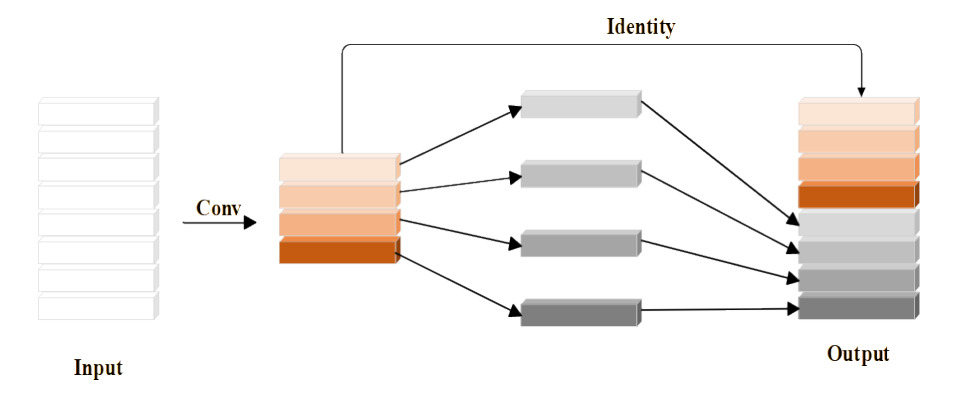
GhostNet12 is a lightweight neural network architecture with the structure shown in Fig. 2. Compared with ordinary convolution to generate feature maps directly, GhostNet first generates fewer intrinsic feature maps through a small number of convolution kernels, and then its core module Ghost applies a simple linear transformation to generate more feature maps, which are called “Ghost” feature maps13,14; they are able to reveal the information in the original feature maps at a small computational cost, which further reduces the computational complexity to reduce the number of parameters and computation amount of the model; finally, the intrinsic and “Ghost” feature maps are combined to reduce the number of parameters and computation amount of the model.
HGnetV2 Module
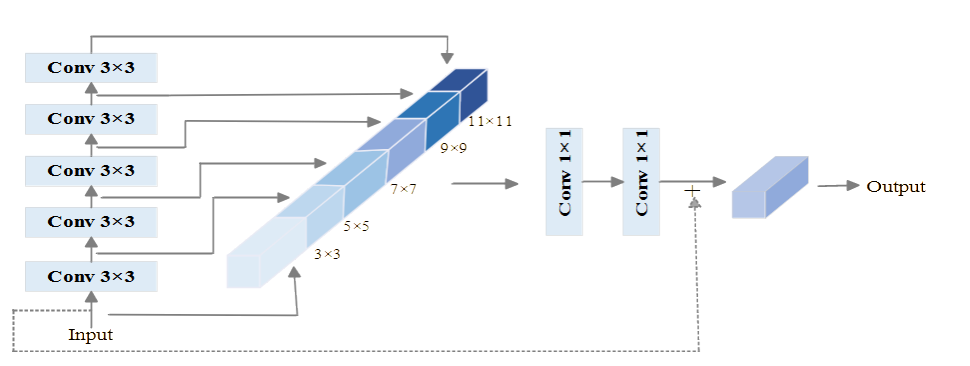
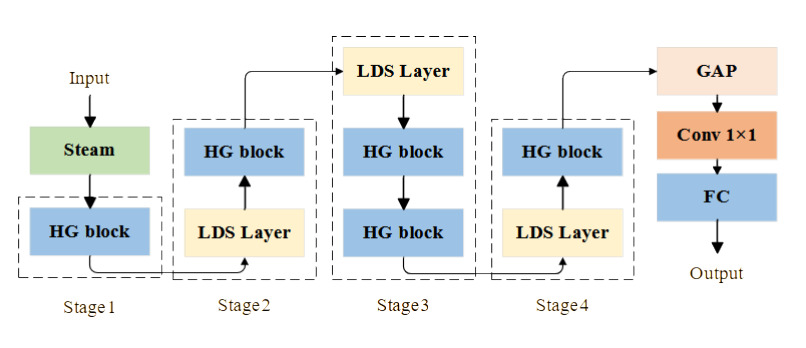
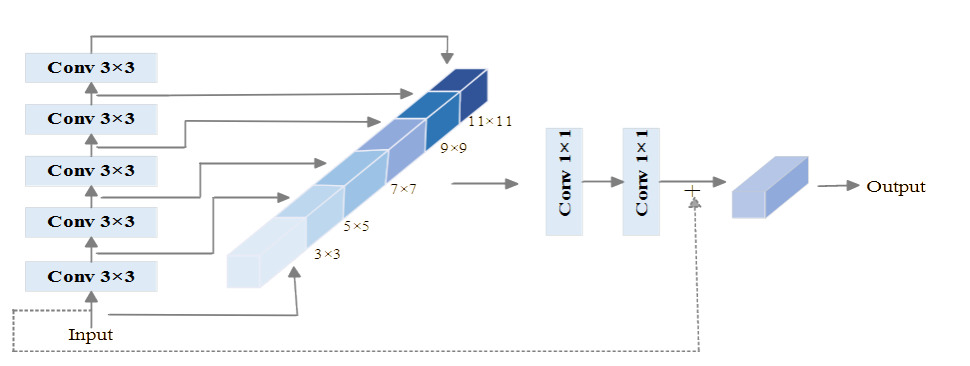
HGNetV2 is a lightweight and efficient backbone network proposed by Baidu,15 and its structure is shown in Fig. 3. Its design focus is similar to that of GhostNet network, which is to reduce the number of parameters and computation of the model while maintaining high accuracy.Steam layer is used as the initial preprocessing layer of the HGNetV2 network. It extracts the initial features from the original input data and passes them to the core component, HG block, which consists of several standard convolutional layers. The structure of HG block is shown in Fig. 4. It handles the data hierarchically and captures richer feature representations while maintaining computational efficiency. Inside each HG block, there are various sub-components which process the data hierarchically to capture richer feature representations while maintaining computational efficiency. A learnable downsampling LDS layer exists in each HG block for reducing the spatial dimension of the feature map as well as reducing the computational load. Then, the GAP layer reduces the spatial dimension of the feature map to one vector per feature map, which helps to improve the robustness of the network to spatial transformations of the input data, and finally, a 1×1 convolutional layer combines the features and maps them to a fully connected layer of the desired output category.16The architectural design of HGNetV2 focuses on hierarchical feature extraction, which permits the learning of complex patterns at different scales and levels of abstraction,17 improving the network’s ability to process image data.
BiFPN
BiFPN (Bi-directional Feature Pyramid Network)18 is an advanced feature pyramid network with the structure shown in Fig. 5, which is mainly used to improve the processing of multi-scale information in target detection and semantic segmentation tasks. Compared to the unidirectional top-down feature propagation of traditional FPN (Feature Pyramid Network) and PANet (Path Aggregation Network), which implements bi-directional connectivity to realize simple feature summation or splicing on top of FPN, BiFPN adds extra edges, fusing more features without adding much cost, treating each bi-directional path as a feature network layer and reusing it many times to achieve higher-level feature fusion and enhance feature expression19; meanwhile, the adaptive feature adjustment mechanism is used to learn the weights, allowing the model to adaptively adjust the fusion method according to the importance of different features, optimizing the fusion of multiscale feature effect, in addition BiFPN removes nodes with only one input edge, thus simplifying the network structure and reducing redundant computation, and improves computational efficiency and speeds up detection by optimizing the feature fusion process while maintaining high accuracy.20

Experimental environment configuration
In this paper, we use the YOLOv8n-seg model provided by Git-hub, and the specific configuration of the experimental training environment is shown in Table 1.
Data set construction
This study was conducted using crayfish as the test subject and was completed using a self-constructed dataset as there was no publicly available dataset then. The image acquisition equipment mainly includes an MVL - MF0828M - 8MP industrial lens (with a focal length of 8mm, F2.8 - F16, and a distortion ratio of 0.28%), a Gigabit Ethernet connection, industrial face array cameras (HIKVISION, MV - CS050 - 10GC, with a resolution of 2248×2048), visual light sources (JL - AR - 12090W), precision lab stands, and a computer. Moreover, to facilitate the application of the research results in real industrial scenarios, the images of the dataset used were all on a single white background. Commercial shrimp of different specifications were purchased from the market, and 234 images of crayfish of different specifications were collected. The acquisition environment is shown in Fig. 6, and some of the acquired images are shown in Fig. 7.


Due to the limited number of samples, the built-in camera of the cell phone was used to expand the number of samples in the dataset and enhance the model’s generalization ability. The crayfish were photographed at different heights and angles in the laboratory environment using the camera. Part of the acquired image is shown in Fig. 8.

The data were subjected to image enhancement processes to expand the dataset and improve model training and generalization ability adequacy. The specific method includes various enhancement operations such as mirror flipping (Fig. 9b), grayscaling (Fig. 9c), and adding noise (Fig. 9d) to the original image (Fig. 9a). Thus, the dataset images were expanded to a total of 1038 images.

The LabelIme tool was used to accurately label the crayfish’s trunk and connect the base of the eyestalk to the end of the caudal segment. It was then saved as a JSON file. The labeling process is shown in Figure 10.

The annotated JSON file is converted to YOLO format and COCO dataset format by code to be divided into a training set and validation set in the ratio of 9:1. The corresponding models are utilized for training, respectively, and the Epoch is set to 200 times.
Evaluation indicators
In this paper, mAP (mean Average Precision) value, Parameters, model size and GFLOPs are used as the evaluation metrics of the model. mAP measures the combined performance of the model’s detection accuracy and localization ability for multiple categories. The number of parameters is the sum of training parameters in the model, and its size directly affects the complexity and learning ability of the model. GFLOPs stands for Giga Floating-point Operations per Second, which represents the number of floating-point operations that can be performed in one second, with the unit being one billion floating-point operations per second. The relevant arithmetic formulas are as follows.
\[ G F L O P s=\frac{2 \cdot H \cdot W \cdot\left(C_{i n} \cdot K^2+1\right) \cdot C_{o u t}}{10^9} \tag{1} \]
\[ A P=\Sigma_{k=1}^n\left(R_k-R_{k-1}\right) \cdot P_k \tag{2} \]
\[ m A P=\frac{1}{N} \Sigma_{i=1}^N A P_i \tag{3} \]
Where the kth recall threshold is the maximum precision value corresponding to ‘n’ is the total number of recall thresholds, is the average precision of the ith category, and ‘N’ is the total number of categories.
Results
GHBSeg-YOLOv8 visualization recognition result
In the current study, to thoroughly evaluate the effectiveness of the GHBSeg-YOLOv8 model in segmenting crayfish body trunks, a meticulous comparative analysis was carried out in contrast to the original YOLOv8n-seg model. This comparative study was designed to comprehensively understand the performance differences between the two models within the specific context of crayfish body segmentation.
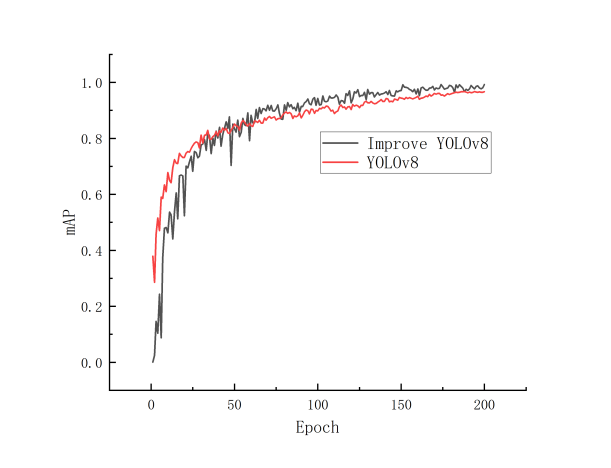
The outcomes of this comparative analysis are graphically presented in Figure 11. In this figure, the mean Average Precision (mAP) curves during the training process for both the GHBSeg-YOLOv8 and the original YOLOv8-seg models are depicted. These mAP curves serve as a crucial visual indicator, clearly reflecting the performance trends of the two models throughout the training phase. It is conspicuous from these curves that the GHBSeg-YOLOv8 model exhibits a significant improvement in segmentation accuracy. Specifically, after the 50 - epoch point during training, the GHBSeg-YOLOv8 model persistently demonstrates superior performance over the original YOLOv8n-seg model, thereby highlighting its enhanced capability in accurately segmenting the body trunks of crayfish.

Moreover, Figure 12 offers a corresponding comparison of the training results obtained from the enhanced YOLOv8n-seg model and the original YOLOv8n-seg algorithm. This comparison further elaborates on the performance characteristics of the GHBSeg-YOLOv8 model. The visual evidence presented in Figure 12 distinctly shows that the improved YOLOv8n-seg model achieves excellent performance in accurately segmenting crayfish tails. In contrast, the original YOLOv8n-seg model frequently fails to detect certain sections of the tail, leading to segmentation results with lower accuracy. This deficiency in the original model further emphasizes the significance of the improvements made in the GHBSeg-YOLOv8 model, especially in achieving more precise segmentation of crayfish body parts, including the tail region.

Discussion
Ablation Experiment
To verify the effectiveness of GhostHGNetV2-Bifpn in improving the YOLOv8n-seg model, several experiments are conducted on the dataset, and the ablation test is designed. Parameters, Size (model size), GFLOPs, and mAP50-95 are selected as the performance evaluation indexes. The ablation test takes the original YOLOv8n-seg algorithm as the base model and introduces Ghost, HGNetV2, and BiFPN in turn. The results of the ablation test are shown in Table 2.
As can be seen from Table 2, after replacing the original backbone network with Ghost and HGNetV2 modules, respectively, the number of model parameters, model size and GFLOPs of the added Ghost module are reduced by a small margin, and the mAP improves by 1.9% on 96.6%; when replacing it with the HGNetV2 module, compared with replacing the Ghost module, the change of each performance evaluation index of the model is are larger, Parameters and model size are reduced by about 28% and 26%, respectively, GFLOP is reduced by 43%, and mAP is improved by 2.9%, reaching a high accuracy value of 99.5%. Combining the Ghost module with the HGNetV2 module to replace YOLOv8’s backbone network for training shows a smaller reduction in all evaluation metrics than just adding and replacing the HGNetV2 module. Retaining the original backbone network of YOLOv8n and introducing the BiFPN module into its neck network, the training results show a significant performance improvement compared to the above-improved modules, with the Parameters and model size reduced by about 39% and 37%, respectively, the GFLOP reduced by 41%, and the mAP improved by 2.5%.
From the above conclusions, it can be seen that the BiFPN module can make the values of model parameter number, model size, and GFLOPs appear to be significantly reduced at the same time that the mAP value is improved, while for the HGNetv2 module, compared with it, the improvement of the first three performance indexes is weaker but more advantageous for improving the mAP value; therefore, replaced the backbone network and neck network with HGNetV2 simultaneously and introduced BiFPN for training, and the results show that the improved model has a 59% reduction in the number of parameters, a 56% reduction in the model size to 3.0 MB, only half the GFLOPs of the original model, and a 1.9% improvement in mAP.
The performance index of Ghost training results is inferior compared with HGNetV2 and BiFPN, but from the training results after combining with the two, respectively, the module can play a small role in improving the model performance after adding. Therefore, the three modules are combined and improved simultaneously, and the final results show that the number of model parameters is reduced by 61%, the model size is reduced by 57% to 2.9MB, the GFLOPs are 5.8, and the mAP is improved by 2.6% to 99.2%. That is, the improved model can achieve lightweight while maintaining high accuracy.
Model Comparison Tests
This paper uses the common segmentation algorithms Mask R-CNN,21 DeepLabV3+,22 and YOLOv5-seg23 to perform comparative experiments with the YOLOv8n-seg segmentation algorithm. We also add the common lightweight improvement modules SeaAttention and MobileNetV3 to YOLOv8n and FasterNet-BiFPN for comparison experiments with the lightweight improvement network proposed in this paper. The experimental results are shown in Table 3.
From Table 3, the YOLO series segmentation algorithms outperform the common Mask R-CNN and DeepLabV3+ segmentation algorithms regarding the number of parameters, model size, and mAP values. YOLOv5-seg, with its similar number of parameters and model size, has a reduced detection accuracy. SeaAttention, a lightweight and efficient attention module, has not achieved good results in adding YOLOv8n-seg, which is the base model of this paper; the training results on this paper’s dataset are unsatisfactory.MobileNetV3 achieves excellent performance on tasks such as image classification, target detection, and semantic segmentation on mobile, similar to the results of adding the SeaAttention module, and the performance on this paper’s dataset is poorer. FasterNet achieves more efficient performance on this paper’s dataset by cutting down on redundant computation and memory access, more efficient extraction of spatial features enables it to achieve higher operating speed than other networks on a wide range of devices while maintaining accuracy on various visual tasks, the training results on this paper’s dataset show a small improvement in performance over the original model, but for the improved GHBSeg-YOLOv8 model lightweighting is low.
Summary and Outlook
In this paper, a lightweight YOLOv8n-seg model is proposed based on shrimp carapace segmentation of Crayfish. The model achieves a lightweight improvement of the basic model by replacing the backbone network with GhostHGNetV2 and introducing the BiFPN module while guaranteeing segmentation accuracy. The size of the best.bt file is only 2.9MB. This file can be converted into an onnx file that is supported by the Ubuntu system and embedded into mobile devices such as NVIDIA development boards to realize the initial hardware deployment. However, the experiments in this study were conducted in a controlled laboratory environment and may not fully encompass the posture of crayfish in real-world situations. Given the dynamic nature of crayfish in natural environments in real-world scenarios, this may result in only part of their bodies being captured under fixed-angle and single-camera shooting conditions. This limitation increases the difficulty of complete segmentation of crayfish. Therefore, future research needs to further explore more advanced algorithms and strategies to better accommodate the segmentation needs of the dynamic characteristics of crayfish.
Acknowledgments
We would like to thank Mr. Wang Aimin for his assistance during this experiment. The Jiangsu Province seed industry revitalization supported this study unveiled list of marshal projects (JBGS[2021]032); Jiangsu Modern Agricultural Industrial Technology System Construction Special Funds Project (JATS[2023]471); National Key Research and Development Program (NKRDP) projects(2023YFD2402000); Yancheng Fishery Quality Development Project(2022yc003)
Authors’ Contribution
Conceptualization: Chunxin Geng (Equal), Aimin Wang (Equal). Data curation: Chunxin Geng (Lead). Formal Analysis: Chunxin Geng (Equal), Cheng Yang (Equal). Investigation: Chunxin Geng (Lead). Methodology: Chunxin Geng (Lead). Software: Chunxin Geng (Lead). Validation: Chunxin Geng (Lead). Writing – original draft: Chunxin Geng (Lead). Writing – review & editing: Chunxin Geng (Equal), Hao Zhu (Equal). Funding acquisition: Aimin Wang (Equal), Zhiqiang Xu (Equal), Yu Xu (Equal), Xingguo Liu (Equal). Resources: Aimin Wang (Lead). Supervision: Aimin Wang (Equal), Cheng Yang (Equal), Zhiqiang Xu (Equal), Yu Xu (Equal), Xingguo Liu (Equal), Hao Zhu (Equal). Project administration: Cheng Yang (Lead).
Competing of Interest – COPE
‘No competing interests were disclosed’.
Ethical Conduct Approval – IACUC
All animal experiments in this study followed the relevant national and international guidelines. Only the crayfish was photographed during the experiment without harming it and returned to the breeding pool after the experiment was completed.
Informed Consent Statement
All authors and institutions have confirmed this manuscript for publication.
Data Availability Statement
Yes, data are available upon reasonable request.